Alexandre de Brevern - ThŤse de Bioinformatique Molťculaire
Prochain: Réseaux neuronaux et alignements
Au-dessus: La structure secondaire
Prťcťdent: La structure secondaire
Méthodes statistiques
Les méthodes statistiques ont été les premières mises en place.
Elles se basent sur une utilisation directe
de la composition en acides aminés et se sont complexifiées avec l'utilisation
de la théorie de l'information et des alignements de séquences.
- -
- Chou et Fasman [29] : La première méthode de prédiction se base sur
la tendance de chaque acide aminé à se trouver associé à une structure
hélice
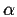 ,
brin
,
brin  ou boucle.
Cette méthode se base sur le calcul d'un coefficient de corrélation pour chaque type d'acide
aminé dans chaque type de structures secondaires. Le taux de prédiction réel de la méthode
dépasse 50 %.
ou boucle.
Cette méthode se base sur le calcul d'un coefficient de corrélation pour chaque type d'acide
aminé dans chaque type de structures secondaires. Le taux de prédiction réel de la méthode
dépasse 50 %.
- -
- GOR : développé initialement par Garnier et collaborateurs, elle a été améliorée
par Gibrat et collaborateurs [62,65,66,61].
GOR I [62] utilise une approche proche
de celle de Chou et Fasman, mais met en valeur les incompatibilités dans les distributions.
La mťthode tient compte des distribution d'angles dièdres [65,66].
Le taux de prédiction dépasse 64 %. Plus récemment, le taux de prťdiction est passť
à plus de 67 % en ajoutant une information binaire dépendante juste de l'hydrophobicité
du type d'acides aminés [104].
- -
- Alignement de séquences : Du fait de l'augmentation des bases de données aussi bien
protéiques que génomiques, il est possible d'utiliser des séquences similaires dans des
techniques de prédiction [68,64,211].
Le principe est séquentiel et consiste à aligner une séquence à prédire avec d'autres séquences
connues, puis à observer dans les zones consensus les compatibilités existantes pour
moduler la prédiction finale.
Par exemple, une procédure bayésienne qui donnait d'un taux de
prťdiction moyen de 67 % passe avec cette mťthode à plus
de 73 % de bonne prédiction [193].
Le programme PREDATOR, lui, passe d'un pourcentage de 68 % à 75 % [60].
Même un nombre limité de séquences dans l'alignement permet des gains significatifs [42].
- -
- Il faut noter que certains algorithmes ne tiennent pas compte de la cohérence séquentielle des
résultats. Ainsi une hélice peut être prédite directement aprés un feuillet
sans avoir de boucles entre les deux ťtats [210].
DSC [105] en revanche s'en préoccupe.
Il utilise un ensemble de paramètres physico-chimiques et en tenant compte des insertions
et des délétions présentes dans l'alignement atteint un taux de 70,1 % seul.
Pour certaines protéines, il dépasse les méthodes de prédiction par
réseau neuronal qui sont décrites dans le paragraphe suivant.
Ainsi, il existe un grand nombre de méthodes fort différentes basées sur des
principes statistiques. L'intérêt majeur de ces méthodes, en regard
des méthodes d'apprentissages type réseaux neuronaux,
est la possibilité de comprendre
les facteurs entrant en jeu dans la prédiction,
donc les acides aminés prépondérants et leurs dépendances éventuelles.
Prochain: Réseaux neuronaux et alignements
Au-dessus: La structure secondaire
Prťcťdent: La structure secondaire
Page 13
(c) 2001- Alexandre de Brevern